
Documentation
Index
1. De quoi s’agit-il ?
Meta-Press.es est un outil pour faire des recherches dans la presse en ligne (presse internationale de référence journaux grand public, revues spécialisées…). Il peut servir par exemple à faire la revue de presse d’une grande association ou même de la veille scientifique (via certaines sources spécialisées). Les recherches s’effectuent par mots clés et vous pouvez sélectionner finement les sources dans lesquelles vous voulez chercher (par type, par langue, par thème, par type de résultat…). L’utilisateur a ainsi une totale maîtrise des journaux dans lesquels la recherche est faite et il lui est même possible d’ajouter ses propres sources.
Il est également possible d’automatiser des recherches pour les répéter chaque jour, chaque mois…
Ce moteur de recherche se présente sous la forme d’une extension pour navigateur web (au format standard WebExtension). Le travail de recherche et de classement des résultats est fait par l’extension elle-même, sur l’ordinateur de l’utilisateur, ce qui permet de lui conférer un grand contrôle de l’outil.
Meta-Press.es indexe déjà des centaines de sources et leur nombre augmente régulièrement.
Avec Meta-Press.es il n’y a pas de serveur central qui surveille et profile les utilisateurs pour adapter les résultats de recherche à leur profil et rajouter de la pub ciblée. Il n’y a donc pas d’effet de bulle comme c’est le cas avec les moteurs de recherche grand public et commerciaux.
Meta-Press.es fonctionne très bien avec le Tor Browser (qui a été conçu entre autre pour lire la presse de manière plus confidentielle qu’avec un navigateur web ordinaire).
Il est sinon recommandé d’utiliser le résolveur DNS Quad9 (via Firefox par exemple) pour éviter les censures administratives locales.
Il fonctionne également sur Android via Fennec F-Droid une version de Firefox pour Android installable depuis la logithèque libre F-Droid.org.
Meta-Press.es est un logiciel libre au code source ouvert. Ceux qui connaissent HTML et JavaScript peuvent se l’approprier et l’adapter à leur usage (ou ajouter facilement de nouvelles sources).
Pour finir, Meta-Press.es est un outil efficace énergétiquement : pas besoin de datacenter au cercle polaire pour faire une recherche dans la presse…
1.1. Limites
Les limites de Meta-Press.es sont de ne chercher que dans les résultats récents (l’accès aux résultats anciens sera disponible prochainement), de ne classer les résultats que par ordre chronologique et de nécessiter d’installer une extension dans son navigateur !
2. Comment ça marche ?
Meta-Press.es est un méta-moteur de recherche qui vous permet d’interroger le moteur de recherche interne de chaque source (renseignée et sélectionnée).
Vous obtenez alors le nombre total de résultats que les sources annoncent avoir sur le sujet, ainsi que les derniers résultats publiés par chaque source.
À chaque requête, le site web des sources est parcouru et vous économisez ainsi le temps que les développeurs ont consacré à automatiser le processus :-)
Ce faisant Meta-Press.es n’active aucun système de suivi publicitaire des utilisateurs, protégeant votre vie privée. L’outil vous redonne par contre le choix de vos sources d’information et liste clairement dans quelles sources il a cherché.
Enfin, une fois votre recherche terminée, vous pouvez sélectionner des résultats et les exporter dans un format réutilisable (RSS, JSON, CSV…). Vous pourrez ainsi les réimporter dans Meta-Press.es ou les utiliser ailleurs (les envoyer par courriel à un ami par exemple, les importer dans un WordPress…).
3. Comment installer l’extension ?
Pour installer Meta-Press.es sur votre navigateur (Firefox ou dérivés, comme le Tor Browser) : ouvrir la page suivante addons.mozilla.org et cliquer sur le gros bouton bleu + Ajouter à Firefox.
4. Comment s’en servir ?
Une fois installée, l’extension crée un bouton dans la barre d’outils, avec l’icône de l’étoile filante de Meta-Press.es.
Figure 1. bouton portant l’icône de Meta-Press.es
Un clic sur ce bouton ouvre un nouvel onglet sur l’interface du moteur de recherche.
Si l’icône n’est pas présente dans la barre d’outils, c’est probablement qu’elle vous attend cachée derrière le menu « pièce de puzzle » des extensions de votre navigateur. Il est alors possible de l’épingler pour l’avoir tout le temps dans la barre d’outils.
Il se peut aussi que vous n’ayez pas autorisé l’extension à fonctionner en mode
"navigation privée" lors de l’installation alors que vous utilisez ce mode de
navigation. Dans ce cas, il est toujours possible de donner cette autorisation
en retrouvant Meta-Press.es dans la liste des addons du navigateur
(accessible depuis son menu principal ou via l’adresse about:addons).
Profitez en pour vérifier que les mises à jour automatiques sont activés pour bénéficier des dernières sources et fonctionnalités.

Figure 2. interface du moteur de recherche
Sous le nom de l’extension dans cet onglet, les gros titres des journaux sélections sont chargés et défilent.
Vous pouvez saisir votre requête et choisir dans quels journaux chercher, grâce au mécanisme multi-critères de filtrage des sources.
Les résultats sont ensuite listés en dessous quand ils arrivent.
Chaque résultats comporte un titre, un lien vers l’article, sa source, sa date, et potentiellement un auteur et un extrait :

Figure 3. détails d’un résultat
Les outils pour travailler sur ces résultats (tri, filtrage, sélection), apparaissent dans la colonne à droite des résultats.
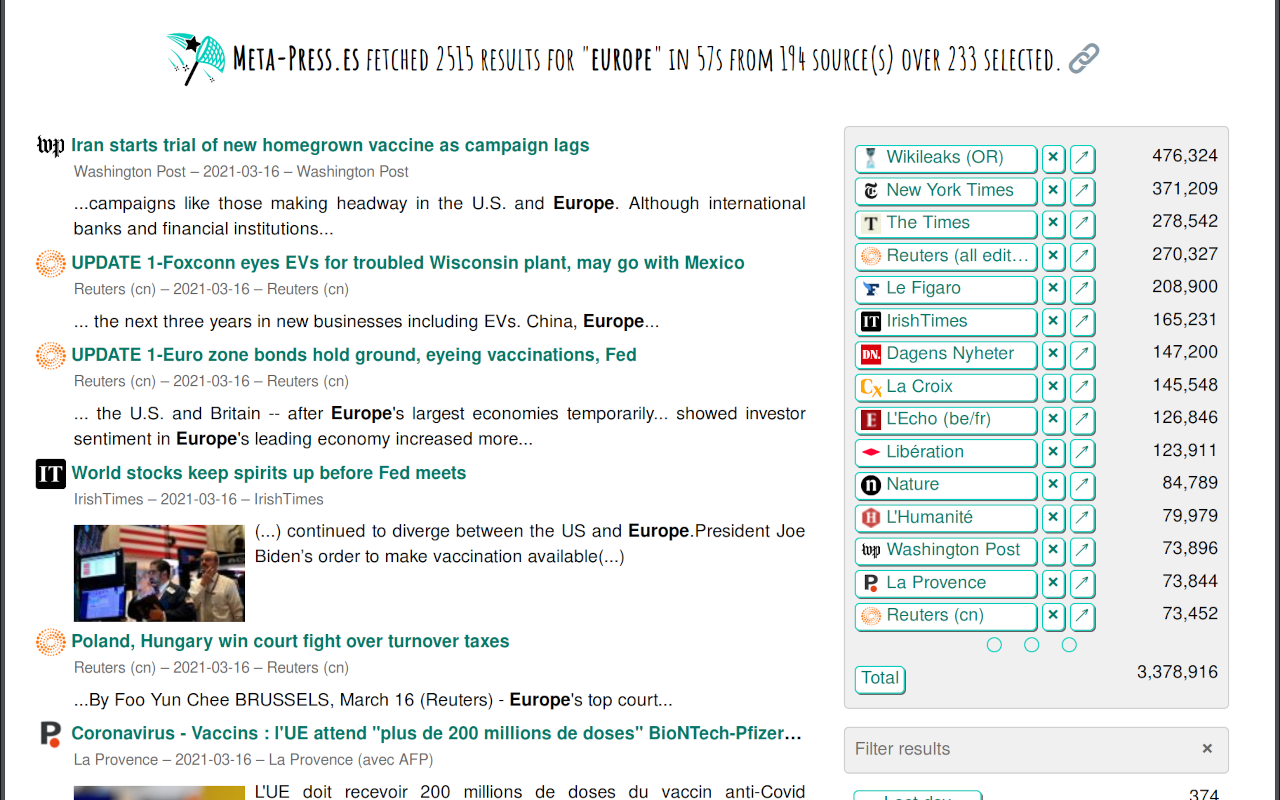
Figure 4. nombre de résultats par source et filtrage par source, en cliquant sur le nom d’une source
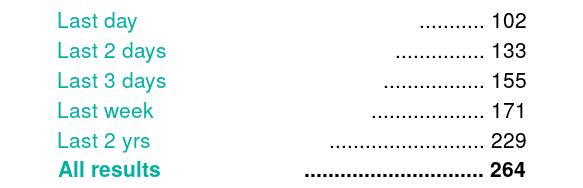
Figure 5. filtrage par date
Vous pouvez par exemple cliquer sur le lien "Toggle selection mode" pour faire apparaître une case à cocher pour chaque résultat et commencer à en sélectionner. Vous pouvez ensuite exporter cette sélection en différents formats (JSON, RSS, ATOM, et bientôt CSV).
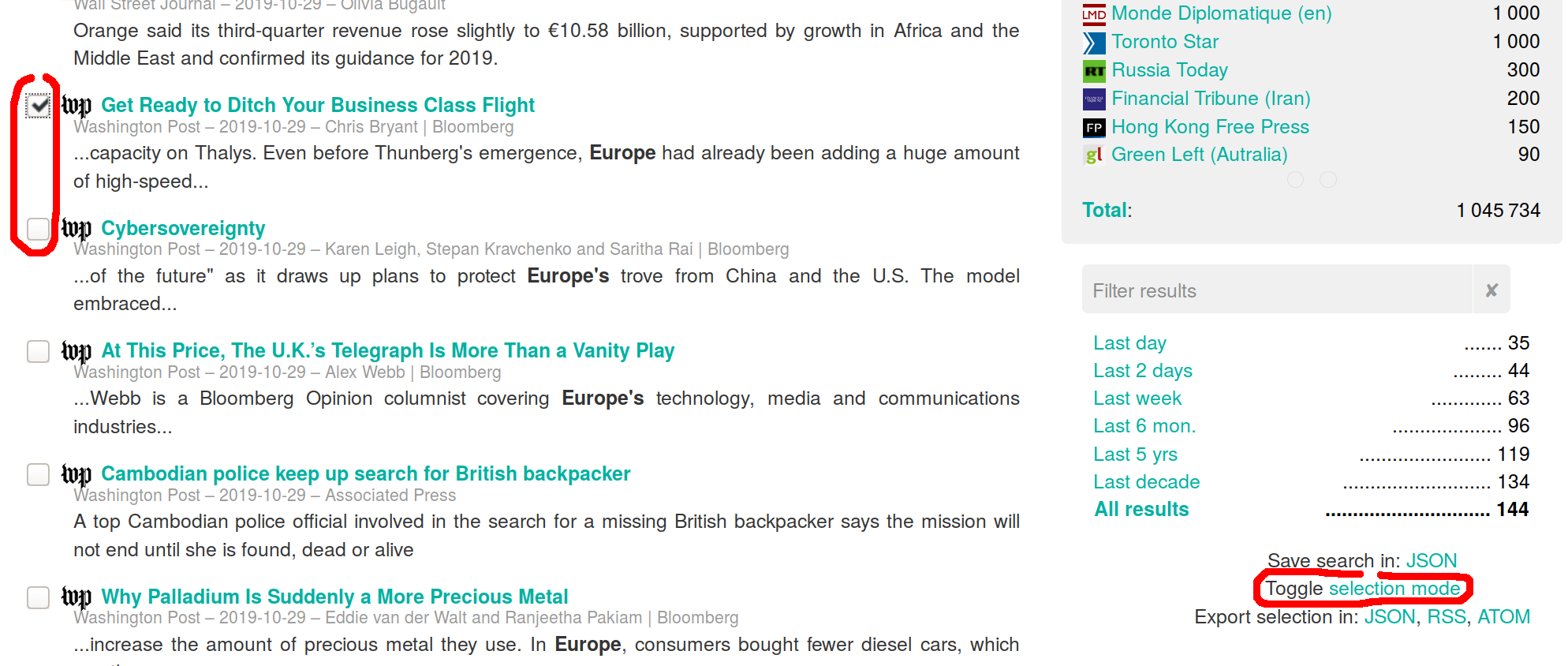
Figure 6. mode de sélection pour export
Pour ré-importer les résultats d’une recherche exportés dans un fichier, cliquez sur le lien "Import JSON" (ou resp. RSS, ATOM) dans la barre horizontale turquoise tout en haut et sélectionnez le fichier en question sur votre disque dur.
4.1. Chercher dans une source précise
Il est possible de choisir une par une les sources dans lesquelles ont souhaite chercher.
Pour cela, il faut déplier le panneau de recherche avancée, en cliquant sur le [ + ] du titre "Recherche avancée [+]". Deux lignes apparaissent alors comportant divers critères et une 3e ligne présente des boutons :
-
remise à zéro des filtres,
-
lister les sources,
-
ajouter une source,
-
automatiser une recherche.
Un clic sur le bouton "Liste des sources" fait apparaitre un 2e volet permettant de parcourir la liste des sources, d’ajouter des sources à la sélection courante ou d’en retirer.
L’icône de loupe, sur chaque ligne de source, permet de régler la prochaine recherche sur cette source uniquement.
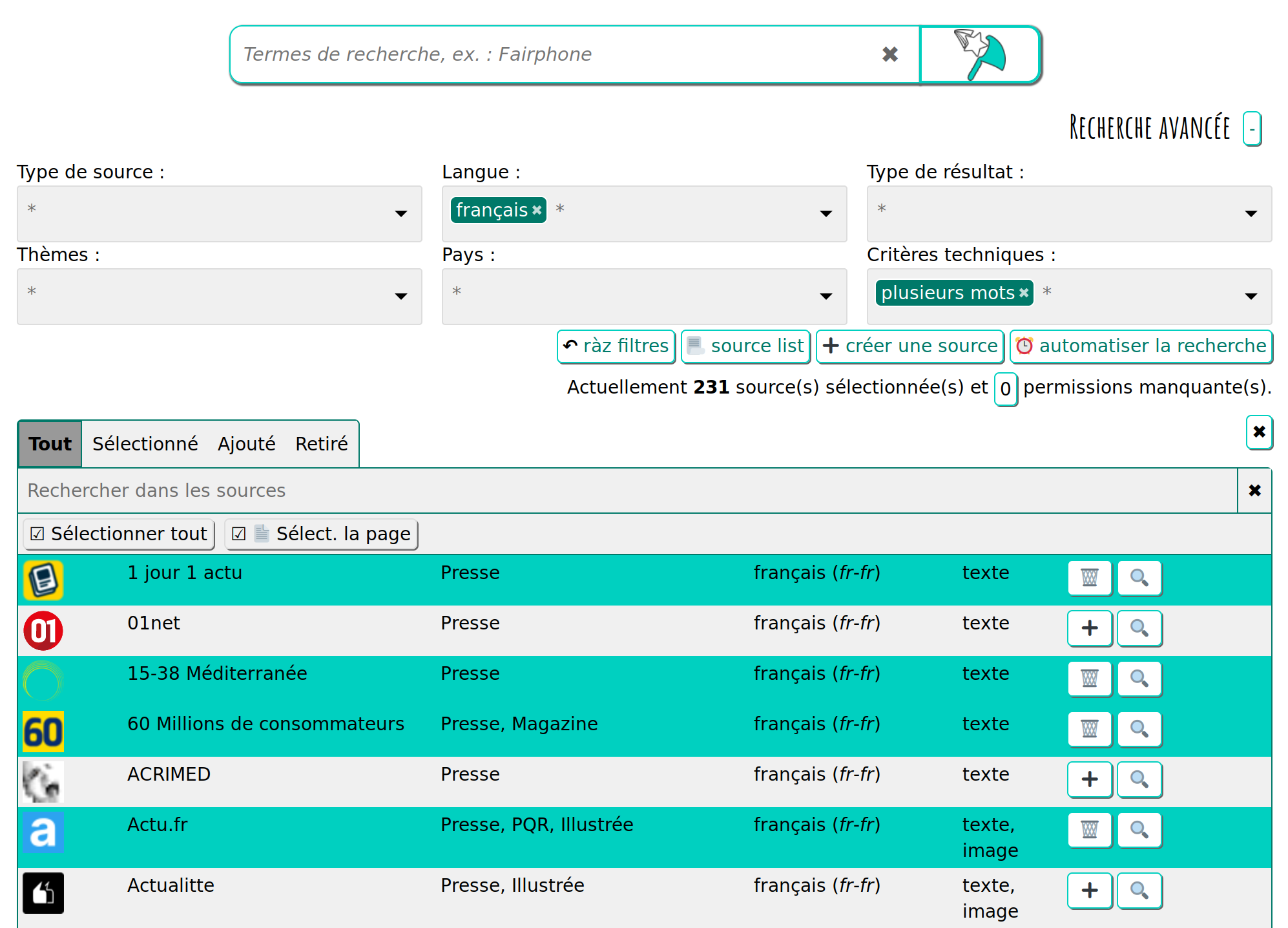
Figure 7. Recherche avancée
4.2. Permaliens et marque-pages
Lorsqu’une recherche est terminée une ligne de statistiques apparait au dessus des premiers résultats. Cette ligne comporte une icône "maillons de chaîne" 🔗 en fin de ligne. Cette icône est un lien permettant de lancer cette recherche à nouveau.

Figure 8. Icône "maillons de chaîne" du permalien
Il est ainsi possible de créer un marque page sur sa recherche favorite, sans avoir à la configurer à chaque fois.
4.3. Recherches programmées
Une fois les termes de recherche saisis et la sélection des sources faites, vous pouvez sauver ces réglages et programmer la recherche pour plus tard au lieu de la lancer immédiatement. Il suffit pour ça de cliquer sur le bouton ⏰ Recherche programmée. Ce bouton ouvre l’onglet des réglages sur la partie réservée à la gestion des recherches programmées.
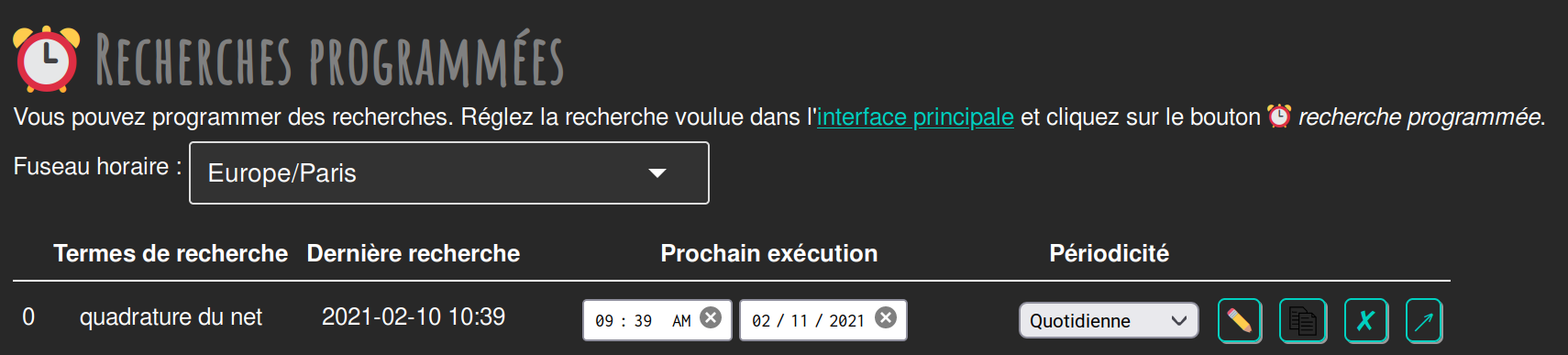
Figure 9. Recherches programmées, avec interface en fond sombre
Ce tableau montre une ligne par recherche programmée. À sa création, une recherche programmée est "Désactivée", mais il suffit de régler la date et l’heure de sa prochaine exécution et de choisir sa périodicité pour qu’elle s’active.
Vous pouvez ainsi programmer une recherche quotidienne en quelques clics.
Des actions sont possibles sur chaque recherche :
-
le 1er bouton, avec un crayon ✏️, ouvre un onglet sur l’interface principale, configurée avec les paramètres de cette recherche (termes de recherche, choix des sources). Si vous modifiez ces réglages vous pouvez les sauver en cliquant sur le bouton de recherches programmées de l’interface principale ;
-
le 2e bouton, avec une icône copier/coller permet de cloner une recherche programmée pour en faire une deuxième, configurée différemment ;
-
le 3e bouton, avec une croix, permet de supprimer une recherche programmée ;
-
le 4e et dernier bouton permet de lancer manuellement la recherche en question.
5. Comment ajouter une source au moteur de recherche ?
Pour ajouter une source à Meta-Press.es, le plus simple est d’utiliser le formulaire de création de source en cliquant sur le bouton « Ajouter une source » depuis l’interface principale. Un nouvel onglet s’ouvre alors sur un formulaire vous guidant pas à pas le long de la démarche.
Ce formulaire ne fonctionne pour l’instant qu’avec les sources servant leurs résultats en RSS, comme c’est le cas de la plupart des journaux basés sur WordPress, le moteur le plus répandu (représentant presque la moitier des sources de Meta-Press.es).
Si le formulaire ne reconnait pas de flux RSS de résultats pour la source que vous voulez ajouter, il vous faudra alors vous penchez sur la 2e méthode, recommandée aux programmeurs.
Si vous êtes un programmeur, ajoutez simplement une entrée dans le fichier json/sources.json.
Une documentation exhaustive a été rédigée pour vous aider dans cette tâche.
 Installation via Mozilla
Installation via Mozilla
 Sources via Framagit
Sources via Framagit
 Sponsor via Liberapay
Sponsor via Liberapay
 Sponsor via HelloAsso
Sponsor via HelloAsso
 Social via Mastodon
Social via Mastodon
 Wau Holland Stiftung
Wau Holland Stiftung
